Steering Agentic Security Scanners with Git Behavioral Graphs
How we use git forensics and behavioral analysis to help agentic AI security scanners find vulnerabilities that static analysis tools miss in enterprise codebases.
The techniques in this post are grounded in Adam Tornhill's Your Code as a Crime Scene (2nd ed., Pragmatic Programmers, 2024). We took those forensic principles and engineered them into a pipeline that steers an AI agent with deterministic precision.
In modern application security, the traditional method of static analysis (SAST) using abstract syntax tree (AST) parsing and call graphs is a well studied, well traveled road. However, traditional scanners lack a fundamental dimension of context: the human element. Vulnerabilities are rarely just syntactical errors; they are the byproduct of diffuse ownership, shifting requirements, and knowledge decay.
.png)
When building our agentic AI security scanner, we faced a hard constraint: LLM context windows are finite, and agentic loops are computationally expensive. Put simply, we can’t just feed a giant monorepo into an LLM and ask it to "please find bugs. K, thx, bye." While we already utilize a hybrid LLM-driven context gathering and SAST-esque multi-agent architecture to surface traditional vulnerabilities - hunting down non-traditional, structural flaws requires an additional layer. For these deeper, complex logic issues, the agent needs a deterministic, high-signal heuristic to prioritize its attention.
To solve this, we introduced a pre-processing pipeline that constructs a Git Behavioral Graph. Before our agent reads a single line of code, it analyzes the repository’s commit history across five distinct behavioral axes.
The Data Ingestion Engine
Parsing git history across a decade-old monorepo is notoriously memory-intensive. Loading the entire commit tree into memory at once guarantees out-of-memory (OOM) crashes.
To solve this, our harvester utilizes an asynchronous subprocess streaming architecture. We pipe git log --numstat with custom delimiters directly into a generator function. This allows us to yield, parse, and evaluate a single commit block at a time, resolving complex git brace rename notations on the fly while maintaining a strictly bounded memory footprint.
With this streaming foundation, we calculate five high-signal behavioral metrics.
1. Code Churn: Quantifying Diffuse Ownership
Code churn is mathematically one of the strongest historical predictors of vulnerability density. [Tornhill, Your Code as a Crime Scene, 2nd ed. code churn as a leading predictor of defect density] Our pipeline extracts total revisions, distinct contributor counts, and cumulative line additions/deletions.
Rather than relying on overly complex models, we look for two highly accurate heuristic anomalies:
- The "Many-Hands" Anti-Pattern: When the number of distinct authors scales linearly with the commit count, ownership becomes completely diffuse. No single engineer holds the comprehensive mental model of the module's security boundaries.
- Security Contract Renegotiation: When a file exhibits a high churn velocity where cumulative deleted lines approximate cumulative added lines, it indicates continuous, heavy rewriting. This is a classic signature of a module whose design is fundamentally unstable and lacks a clean architectural reset.
AI entities (Codex, Claude, etc.) do not improve the situation here or level of risk. Arguably, the opposite is true. They are not humans with long term knowledge and storage. They have a point-in-time concept of the changing code with discrete directions, narrow focus, and the range of contributors can now widen with increased shipping velocity. Suddenly your support team can complete their own tickets. Marketing can write their own plugins.
2. Temporal Coupling: Mapping Invisible Dependencies
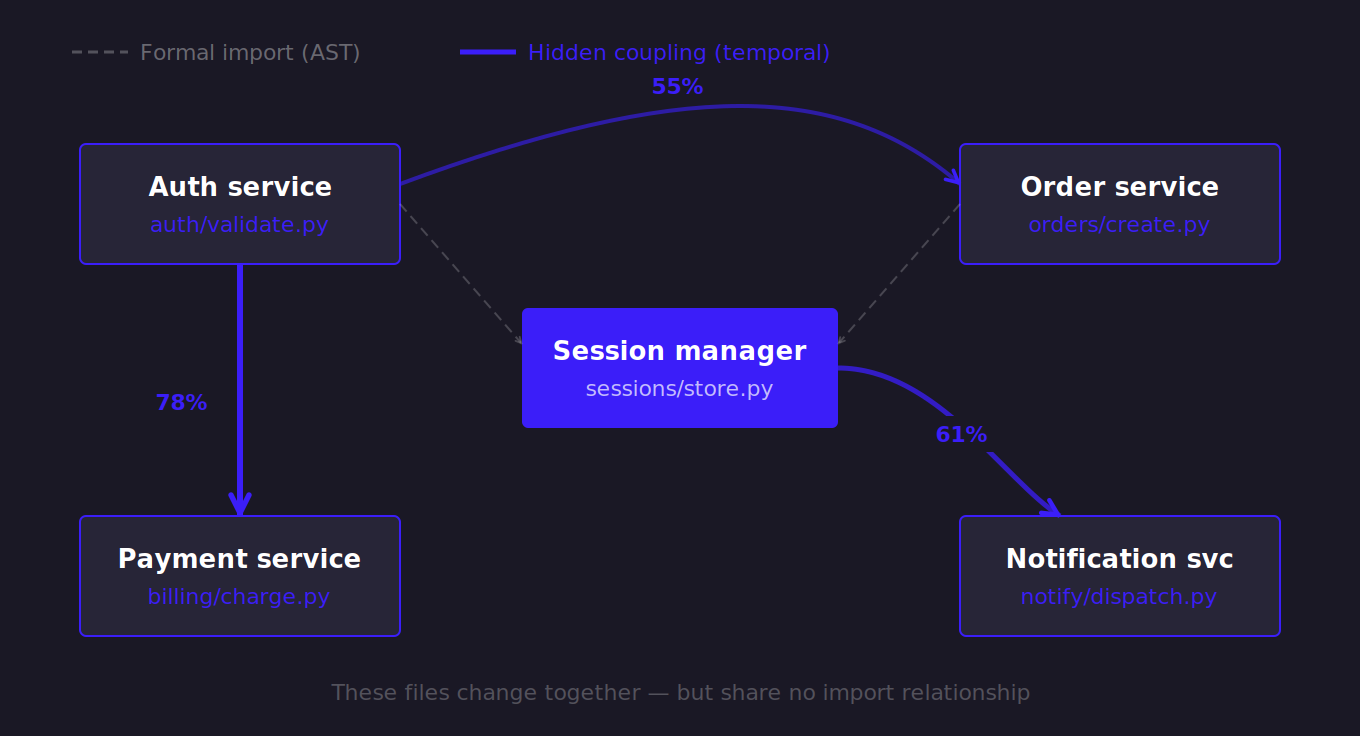
Attackers exploit the invisible gaps between microservices. To find these, we utilize temporal coupling—a forensic graph technique that identifies files that frequently change together in the same changeset, regardless of whether a formal AST import relationship exists.[Tornhill, Your Code as a Crime Scene, 2nd ed. — temporal coupling / change coupling as a method for discovering hidden architectural dependencies]
We model this as a bipartite graph of commits to files. To calculate the coupling degree, we look at the ratio of shared revisions to the average individual revision count of the pair:
.png)
Algorithmic Optimizations: Graph algorithms can easily explode in computational complexity. To keep our scanner highly performant, we apply strict pruning heuristics:
- Changeset Caps: We ignore massive, repo-wide refactors (e.g., license header sweeps) by filtering out any commit touching more than 30 files.
- Cold File Pruning: A file pair must have a baseline history of at least 5 individual revisions. This prevents a cold file from generating a spurious 100% coupling degree after a single co-commit.
- Aggressive Garbage Collection: Every 5,000 commits, our streaming engine pauses to prune pairs that only share a single co-commit. Because of our minimum revision threshold, a single co-commit can mathematically never reach our 50% target threshold, making it pure noise safe for garbage collection.
3. Knowledge Decay: Age and Ownership Concentration
Age and ownership determine if anyone actively understands a critical module. We track this by combining two straightforward metrics:
- Age in Months: Calculated by diffing the file's last modified timestamp against current UTC time. High-age files often rely on deprecated cryptographic wrappers or broken standards (MD5, HTTP Basic Auth) that were patched everywhere else but forgotten here.
- Ownership Concentration: We calculate the fraction of a file's total surviving code attributed to its primary contributor. If a single developer owns over 90% of a heavily modified file, it acts as a knowledge silo—if they leave, the implicit security context evaporates.
4. Temporal Anomalies: Circular Statistics for Threat Hunting
To identify compromised CI pipelines or insider threats, we flag commits made at statistically unusual hours. However, standard linear math fails on clocks—the linear mean of 23:00 and 01:00 is incorrectly calculated as 12:00, destroying the signal.
Instead, we map commit timestamps onto a unit circle using circular statistics. We extract the decimal hour ($HH + \frac{MM}{60}$) and convert it to an angle in radians:
.png)
We compute the mean of the sine and cosine components across an author's history to find their true circular mean, and calculate the circular standard deviation based on the shortest angular distances.
If a commit's angular distance from the author's circular mean exceeds $3.0\sigma$, it triggers an anomaly. To aggressively filter noise, we mandate a baseline commit history per author and completely ignore any anomalies occurring within standard local business hours (9 AM–5 PM).
5. Intent Mining: The Developer Confessional
Developers narrate their architectural shortcuts in commit messages. Keywords like "bypass," "hardcode," or "remove before" function as explicit confessions of technical debt.
While searching commit messages is trivial with regex, making it actionable for an AI agent is a data projection problem. Historically interesting hacks on files that no longer exist waste the LLM's finite context window.
Therefore, our pipeline strictly intersects the regex matches with the output of git ls-files. If a commit confesses to a "quick fix" and the files modified in that specific commit still exist in the current working tree, the agent is directed to analyze those live paths for latent bypass surfaces. To prevent sensitive data leaks into the LLM context, all matched commit messages are routed through a dedicated secrets sanitizer before being passed to the planner.
How We Orchestrate the Agent: Using Deterministic Code Quality to Bound AI StochasticityIn software engineering, classic code quality metrics like cyclomatic complexity, code churn, and temporal coupling are traditionally used to predict maintenance burden and technical debt. However, from an AppSec perspective, maintenance burden is computationally indistinguishable from security risk. Where code quality degrades, structural entropy rises, and vulnerabilities inevitably breed.
A seasoned human security auditor does not read a monorepo linearly from main.py. They operate on heuristics and intuition: they check git blame on the cryptographic wrappers, they look for the auth module everyone hot-patches but nobody actually owns, and they zero in on the files littered with "TODO: fix bypass later" comments. By building this Git Behavioral Graph, we are explicitly digitizing and scaling that human intuition into a deterministic data structure. [Tornhill, Your Code as a Crime Scene, 2nd ed. the core thesis: applying forensic psychology to treat git history as behavioral evidence]
This is crucial because Large Language Models are inherently stochastic engines. If deployed naively against a massive codebase, they suffer from context fragmentation, attention decay, and hallucination. By pre-processing the repository into this behavioral artifact, we fundamentally alter the agent's execution model. We use deterministic, mathematically rigorous algorithms to tightly bound the search space. Only then do we unleash the LLM's stochastic reasoning to evaluate the semantics within that bounded space.
.png)
We no longer ask our agent to blindly "find vulnerabilities" in a vacuum. We provide it with a prioritized, JSON-structured map of human risk pointing its finite context window precisely at the highly-coupled, heavily-churned, late-night architectural hacks. This synthesis of deterministic graph analysis and agentic semantic reasoning is what allows us to scale elite, human-level security auditing across enterprise codebases.
If you’re building AI-powered security tooling and want to talk through how behavioral analysis fits into your pipeline, we’d love to hear from you.
The behavioral analytics in this post are built on techniques pioneered by Adam Tornhill. For a deep dive into the theory:
- Your Code as a Crime Scene, Second Edition - Adam Tornhill (Pragmatic Programmers, 2024) - pragprog.com/titles/atcrime2
- Software Design X-Rays - Adam Tornhill (Pragmatic Programmers) – also worth reading for change coupling algorithms



