Why we wrote “Building Secure AI Applications” and how it helps teams build secure LLM features without slowing down
Everywhere I go, I meet teams who are building with LLMs even if they do not describe it that way. They might say they are adding a new search feature, or experimenting with an internal copilot, or stitching a model into an existing workflow. The label changes, but the truth is the same. Modern software now has an LLM somewhere inside it. This shift is happening fast, often faster than the security thinking behind it.
As we spent the last year talking with customers and prospects, a pattern kept showing up. Teams were treating LLM features the way they used to treat web apps or APIs. They were assuming the threat model was similar. It is not.
When you add a model to your product, you are no longer only dealing with input validation and classic injection flaws. You are dealing with unpredictable behavior, semantic vulnerabilities, retrieval-based mistakes, and agents that can take actions in ways traditional code scanners were never designed to understand.
The OWASP Top 10 for LLM Applications captured this problem clearly. Prompt injection. Data and model poisoning. System prompt leakage. Misinformation. Unbounded consumption. Anyone who has spent time with real production LLM systems knows these are not theoretical risks. They appear the moment a model starts touching real code, real data, and real users.
We wrote this white paper to give engineering and security leaders a practical guide to understanding this new class of risk.
We wanted to show where these failures actually happen in real systems, not in abstract research. We also wanted to give teams a sense of what good looks like. Not perfection but a path. Something they can point to when they are building or reviewing design decisions.
What to expect
Inside the white paper, we walk through every OWASP LLM risk. We explain what the risk is, why it matters in real environments, and how it has shown up in actual incidents. We talk about what attackers are doing today and what controls help most. The paper also includes a reference architecture that shows where guardrails belong.
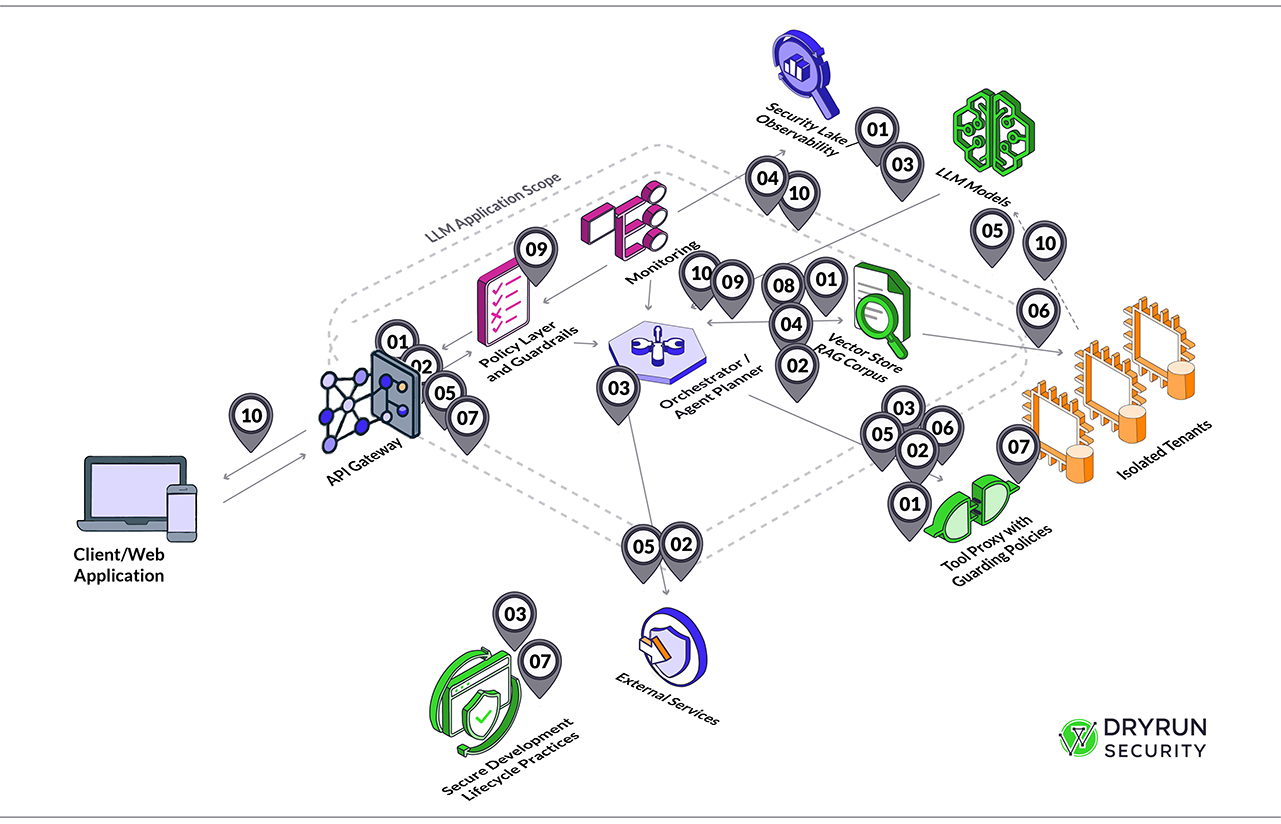
For example, how a policy layer outside the model can mediate prompts, how a tool proxy lets you enforce least privilege for agents, how vector stores become a new data perimeter, and why you need structured outputs before anything reaches a downstream system.
Teams kept telling us they needed something actionable. So we also included a control checklist. It maps each OWASP risk directly to the part of the system where the mitigation belongs. API gateway, orchestrator, policy layer, retrieval pipeline, vector store, SDLC, and monitoring. If you are wondering who should own what or where the work should sit, this helps clarify it.
One of the highlights of the project came from a conversation with Adam Dyche at Commerce. They are deep into AI driven shopping experiences and they are doing it with intent. Adam said that OWASP LLM risks are really about context and that they wanted to build security in from the beginning.
Adam said DryRun Security outperformed every other tool they tested because it understood the code the way their engineers did.
It was a reminder to me that teams do not want magic. They want clarity. They want tools that see the real environment they are building, not a generic pattern matcher that was designed for yesterday’s applications.
The truth is simple. Most teams are shipping LLM features faster than their security practices are evolving. It’s not because they do not care. It’s because the old mental models no longer fit. Traditional code scanners miss the majority of LLM specific vulnerabilities because they were never designed to inspect model planners, tool interfaces, RAG pipelines, embeddings, or agent frameworks. They cannot reason about behavior that emerges at runtime. They can only look for the patterns they already know.
Our work at DryRun sits directly in that gap. We focus on context and code intent. We help teams catch missing guardrails, unsafe prompt handling, weak tool usage, insecure RAG pipelines, over privileged agents, and code paths that can lead to runaway token use. These are problems that only show up when the model meets the application. And that is exactly where teams are struggling today.
But this white paper is not about us. It is about the shift happening across the industry. Developers are now responsible for part of the AI attack surface. Security teams are learning a new language.
Everyone is trying to figure out what good looks like.
Our goal is to give you a clear starting point and a map you can use no matter what tools you choose.
If your team is building with LLMs today or planning to, this paper will give you a deep understanding of the top ten risks, a proven reference architecture, and a checklist you can use during design, review, and implementation. It will help you build faster with fewer surprises and with the guardrails needed for systems that behave differently from anything we have built before.
You can read it here: Building Secure AI Applications
My hope is that it helps teams ship great AI features without losing sight of security in the process. This new era of software is full of opportunity. We just need to build it with clear thinking, strong controls, and a willingness to evolve our practices alongside the technology.

.jpg)

